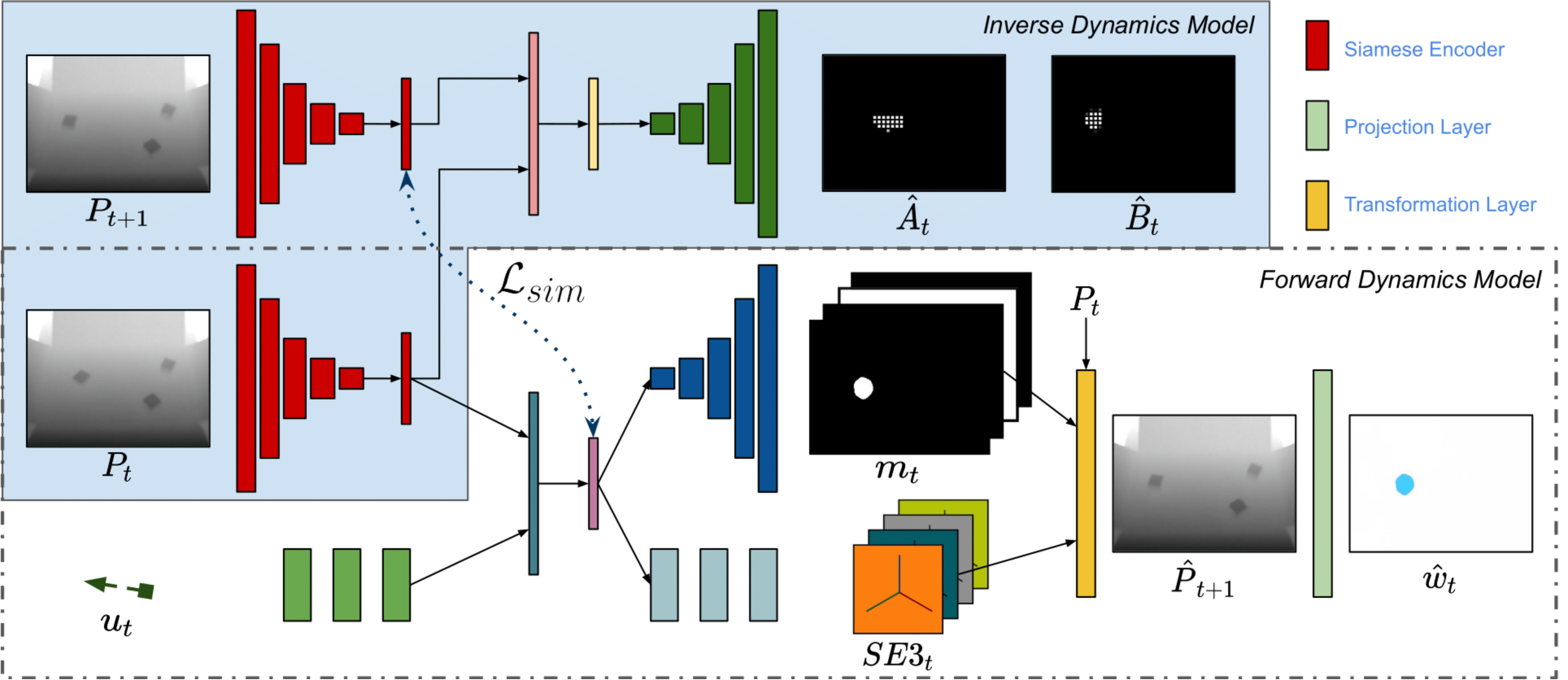
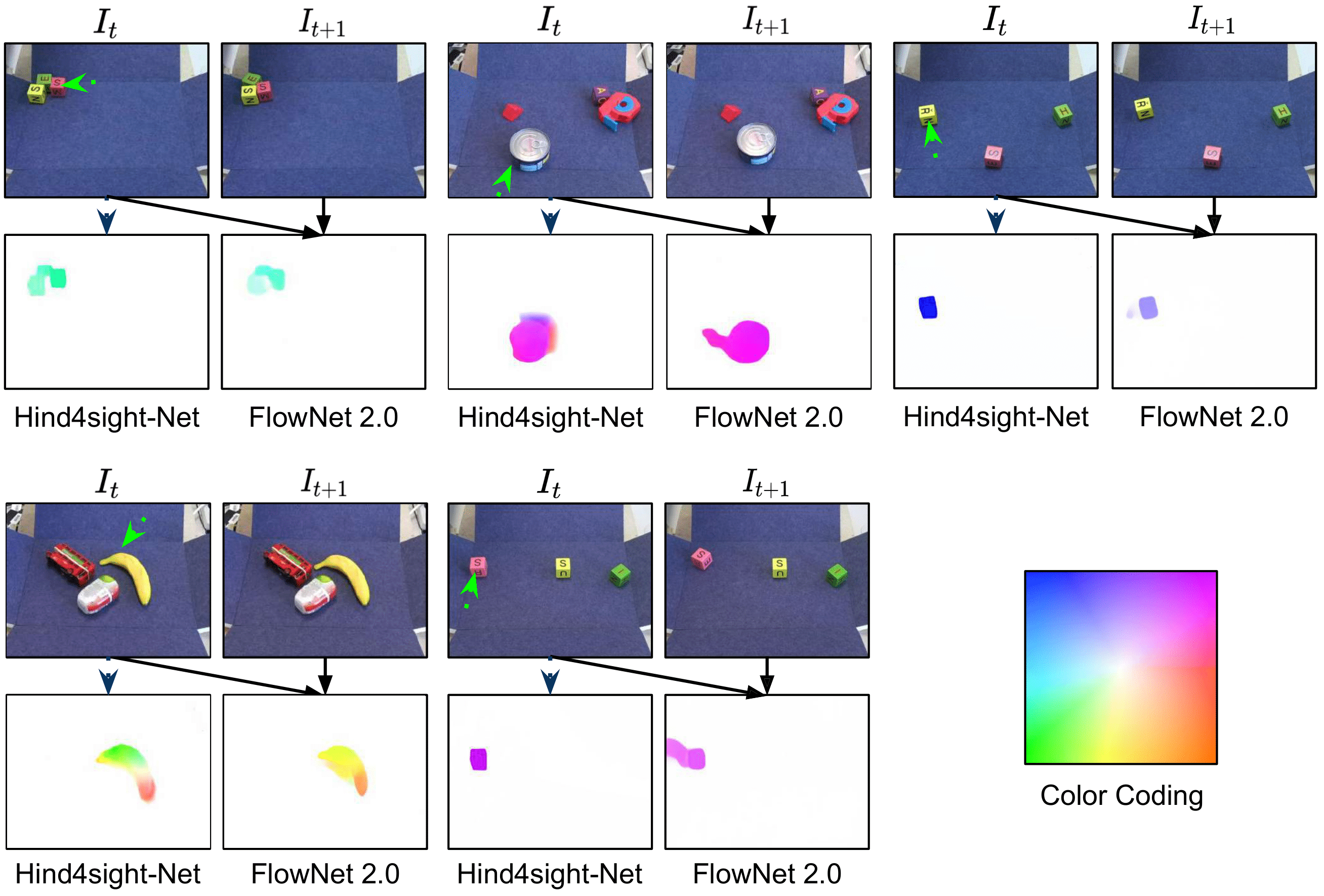
What will happen if the robot shown in the figure moves the arm to the left? We can all foresee that the tape dispenser will move to the left, probably colliding with the banana. Intelligent beings have the remarkable ability to effectively interact with unseen objects by leveraging intuitive models of their environment’s physics learned from experience. Predicting the effect of one’s actions is a cornerstone of intelligent behavior and also enables reasoning about sequences of actions needed to achieve desired goals. Thus, the ability to learn dynamics models autonomously from physical interaction provides an appealing avenue for improving a robot’s understanding of its physical environment, as robots can collect virtually unlimited experience through their own exploration.

Hindsight for Foresight:
Unsupervised Structured Dynamics Models from Physical Interaction
Iman Nematollahi, Oier Mees, Lukas Hermann, Wolfram Burgard